PDiT: Interleaving Perception and Decision-making Transformers for Deep Reinforcement Learning
Abstract
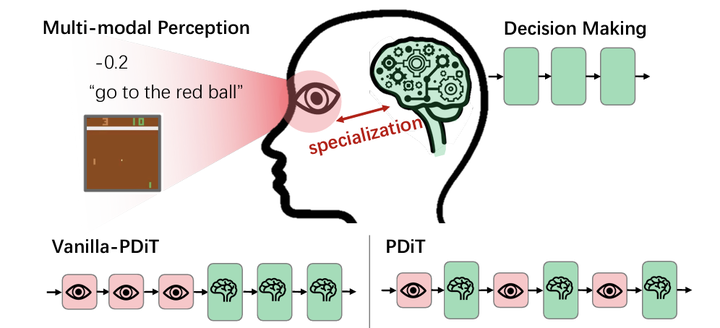
Designing better deep networks and better reinforcement learning (RL) algorithms are both important for deep RL. This work studies the former. Specifically, the Perception and Decision-making Interleaving Transformer (PDiT) network is proposed, which cascades two Transformers in a very natural way: the perceiving one focuses on the environmental perception by processing the observation at the patch level, whereas the deciding one pays attention to the decision-making by conditioning on the history of the desired returns, the perceiver’s outputs, and the actions. Such a network design is generally applicable to a lot of deep RL settings, e.g., both the online and offline RL algorithms under environments with either image observations, proprioception observations, or hybrid image-language observations. Extensive experiments show that PDiT can not only achieve superior performance than strong baselines in different settings but also extract explainable feature representations. Our code is available at https://github.com/maohangyu/PDiT.
TL;DR: In PDiT, we proposed a Transformer-interleaving-Transformer architecture for specialized environment perception and decision-making: it is a multi-modal generalist agent for vision, language, and numerics!