Abstract
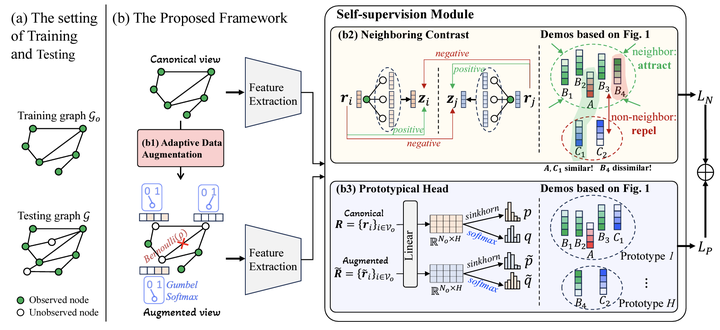
Kriging aims at estimating the attributes of unsampled geo-locations from observations in the spatial vicinity or physical connections, which helps mitigate skewed monitoring caused by under-deployed sensors. Existing works assume that neighbors’ information offers the basis for estimating the attributes of the unobserved target while ignoring non-neighbors. However, non-neighbors could also offer constructive information, and neighbors could also be misleading. To this end, we propose ``Contrastive-Prototypical’’ self-supervised learning for Kriging (KCP) to refine valuable information from neighbors and recycle the one from non-neighbors. As a pre-trained paradigm, we conduct the Kriging task from a new perspective of representation: we aim to first learn robust and general representations and then recover attributes from representations. A neighboring contrastive module is designed that coarsely learns the representations by narrowing the representation distance between the target and its neighbors while pushing away the non-neighbors. In parallel, a prototypical module is introduced to identify similar representations via exchanged prediction, thus refining the misleading neighbors and recycling the useful non-neighbors from the neighboring contrast component. As a result, not all the neighbors and some of the non-neighbors will be used to infer the target. To encourage the two modules above to learn general and robust representations, we design an adaptive augmentation module that incorporates data-driven attribute augmentation and centrality-based topology augmentation over the spatiotemporal Kriging graph data. Extensive experiments on real-world datasets demonstrate the superior performance of KCP compared to its peers with 6% improvements and exceptional transferability and robustness.