VisionTraj: A Noise-Robust Trajectory Recovery Framework based on Large-scale Camera Network
Abstract
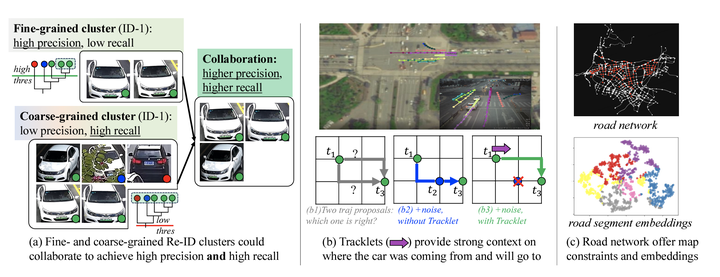
Trajectory recovery based on the snapshots from the city-wide multi-camera network facilitates urban mobility sensing and driveway optimization. The state-of-the-art solutions devoted to such a vision-based scheme typically incorporate predefined rules or unsupervised iterative feedback, struggling with multi-fold challenges such as lack of open-source datasets for training the whole pipeline, and the vulnerability to the noises from visual inputs. In response to the dilemma, this paper proposes VisionTraj, the first learning-based model that reconstructs vehicle trajectories from snapshots recorded by road network cameras. Coupled with it, we elaborate on two rational vision-trajectory datasets, which produce extensive trajectory data along with corresponding visual snapshots, enabling supervised vision-trajectory interplay extraction. Following the data creation, based on the results from the off-the-shelf multi-modal vehicle clustering, we first re-formulate the trajectory recovery problem as a generative task and introduce the canonical Transformer as the autoregressive backbone. Then, to identify clustering noises (e.g., false positives) with the bound on the snapshots’ spatiotemporal dependencies, a GCN-based soft-denoising module is conducted based on the fine- and coarse-grained Re-ID clusters. Additionally, we harness strong semantic information extracted from the tracklet to provide detailed insights into the vehicle’s entry and exit actions during trajectory recovery. The denoising and tracklet components can also act as plug-and-play modules to boost baselines. Experimental results on the two hand-crafted datasets show that the proposed VisionTraj achieves a maximum +11.5% improvement against the sub-best model.